13 октября 2025
data & machine learning
От идеи до модели — практический путеводитель по ML-проекту
Machine Learning
ETL
MAE/MSE
Feature Engineering
В этой статье пройдём ключевые этапы жизненного цикла ML-проекта: от формулировки бизнес-задачи и подготовки данных до обучения модели, её валидации и деплоя с мониторингом. Цель — показать практический, повторяемый рабочий процесс, который можно адаптировать под конкретный случай.
Формулировка задачи и метрик
Успех ML-проекта начинается с ясной формулировки: что мы хотим прогнозировать/оптимизировать и какие метрики важны (precision/recall, ROC-AUC, MAE, бизнес-метрики). Закрепите целевую метрику и критерии успешного запуска.
Рекомендации по метрикам
- Для несбалансированных классов — precision/recall/F1.
- Для регрессии — MAE/MSE, но проверяйте интерпретируемость.
- Для бизнес-решений — привязывайте метрики к KPI: LTV, churn, retention.
Сбор и подготовка данных
Качественный датасет — 80% успеха. Сбор включает источники (BBDD, события, логи), очистку (удаление дубликатов, аномалий), заполнение пропусков и создание признаков.
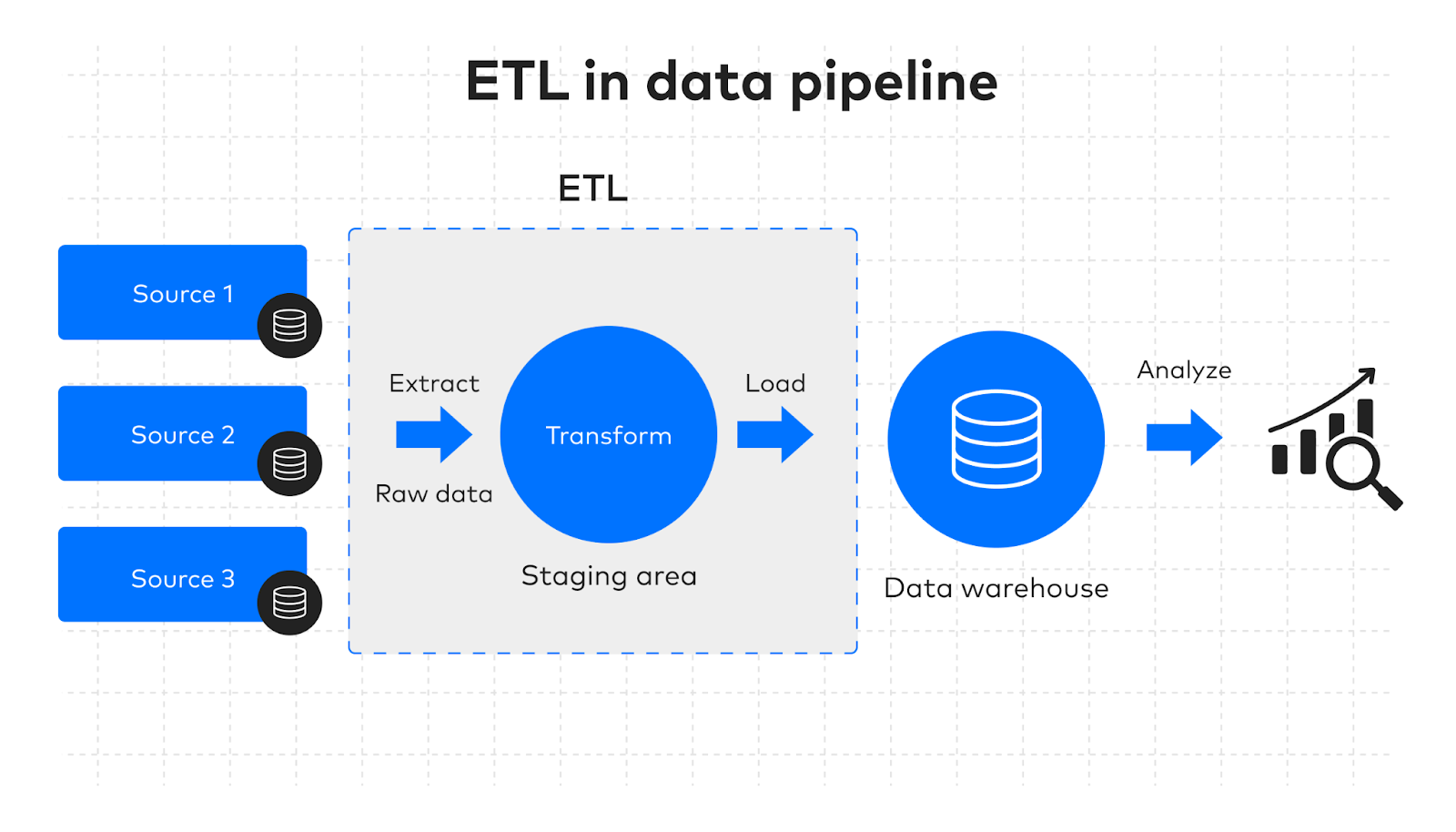
схема ETL/ELT-пайплайна
Чеклист подготовки данных
- Инвентаризация источников и полей.
- Обработка пропусков и аномалий.
- Нормализация/скейлинг и кодирование категорий.
- Временные разрезы и разделение на train/val/test.
Feature engineering — кратко
Создание информативных признаков (агрегации, временные признаки, взаимодействия) часто даёт больше выгоды, чем смена модели.
Выбор модели и обучение
Начинайте с простых моделей (логистическая регрессия, решающие деревья), затем переходите к ансамблям и бустингу. Для сложных задач — нейросети. Важно иметь репродуцируемый эксперимент-трекер.
Используйте кросс-валидацию, контроль по отложенному тесту и временные сплиты для временных рядов. Оценивайте стабильность признаков и дрейф.
Пример графика метрик по эпохам или кросс-валидации
Деплой и MLOps
Модель должна работать в окружении продакшена: контейнеризация, CI/CD для моделей, версионирование артефактов и автоматизированный мониторинг.
Ключевые элементы MLOps
- Управление версиями данных и моделей.
- Автоматические тесты моделей (smoke tests, data tests).
- Мониторинг SLO/SLI для предсказаний и качества данных.
- Автоматические механизмы отката и обновления фич.
Заключение
ML-проект — это командная дисциплина: успех зависит не только от модели, но и от данных, инженерных практик и процессов внедрения. Следуя простому, повторяемому пайплайну (формулировка → данные → модель → деплой → мониторинг), команды уменьшают риски и повышают ценность аналитики для бизнеса.
